Allgemeine Richtlinien für alle Sprachen
Einleitung
Allen Kapiteln wurde eine eindeutige Nummerierung, der Richtliniennummer, hinzugefügt, um eine eindeutige Identifikation zu ermöglichen. Jede Richtliniennummer besteht aus dem Buchstaben GL(General Languages) gefolgt von einer Nummer, die den Abschnitt identifiziert. Damit kann eine Regel eindeutig identifiziert werden, z.B. für ein Code-Review.
GL1 Zielgruppe
Weisheit
Code wird öfters gelesen als geschrieben.
Schreibe Code und Dokumentation so, als würdest du für andere Entwickler schreiben, die deinen Code lesen werden. Frage andere Entwickler, ob sie deinen Code verstehen und ob sie dir Feedback oder Verbesserungsvorschläge geben können.
Senior-Entwickler vs. Junior-Entwickler
Beim Verständnis von Code sollte es keine Rolle spielen, ob der Entwickler ein Senior- oder Junior-Entwickler ist. Die große Erfahrung bei Senior-Entwicklern kann dazu führen, dass sie unnötig komplexen Code schreiben, der nicht nur für Junior-Entwickler schwer zu verstehen ist. Es ist daher wichtig, dass Code so geschrieben wird, dass er von jedem Entwickler verstanden werden kann. Beide Seiten sollen von der Zusammenarbeit profitieren und voneinander lernen.
Junior-Entwickler sollen sich nicht scheuen, Fragen zu stellen, wenn sie etwas nicht verstehen. Dagegen sollen Senior-Entwickler offen für Fragen sein und bereit sein, ihr Wissen zu teilen, denn auch sie waren einmal Junior-Entwickler. Dadurch können Junior-Entwickler viel lernen und werden so schneller zu wertvollen Teammitgliedern.
GL2 Anwendung der Prinzipien der Softwareentwicklung
Die Prinzipien der Softwareentwicklung wie in Prinzipien der Softwareentwicklung beschrieben, sollen befolgt werden, um sicherzustellen, dass der Code sauber, robust und wartbar bleibt.
GL3 Abstraktionsschichten
Ein Projekt soll in Abstraktionsschichten aufgeteilt werden, um die Verantwortlichkeiten zu trennen und die Wartbarkeit zu verbessern. Diese Schichten sind, aber nicht ausschließlich:
- Präsentationsschicht (Benutzeroberfläche)
- Geschäftslogikschicht (Domänenlogik)
- Datenzugriffsschicht (Datenbankzugriff)
Dazu soll Dependency Injection verwendet werden, um die Abhängigkeiten zwischen den Schichten zu verwalten. Jede Schicht kommuniziert über Schnittstellen (Interfaces) mit den anderen Schichten.
Fehlen von Abstraktionsschichten
Das Unterlassen einer Trennung zwischen den Schichten führt zu einem unübersichtlichen und schwer wartbaren und testbaren Code.
Die auch nachträgliche Einführung von Abstraktionsschichten ist zuerst aufwändig, aber langfristig führt es zu einer deutlichen Verbesserung der Situation.
Neue Entwickler können sich zudem schneller in den Code einarbeiten, da sie nicht die gesamte Anwendung verstehen müssen, sondern nur die Schicht, in der sie arbeiten.
GL4 Anwendung von Design Patterns
Design Patterns bieten eine wiederverwendbare Vorlage zur Lösung von Softwareentwicklungsproblemen in einem bestimmten Kontext. Sie dienen dazu, den Code sauberer, effizienter und einfacher zu verstehen zu machen. Einige Beispiele für Design Patterns, die in Java häufig verwendet werden, sind:
- Klassenfabrik (Factory Pattern)
- Singleton Pattern
- Builder Pattern
- weitere Patterns dofactory Design Patterns
GL5 Architektur planen und umsetzen
Der Code soll nach den Prinzipien der Softwareentwicklung in Prinzipien der Softwareentwicklung strukturiert werden.
Darunter fallen, jedoch nicht ausschließlich:
- Aufteilung in Abstraktionsschichten
- Trennung von Verantwortlichkeiten
- Trennung von Geschäftslogik und Präsentation
- Nutzung von Dependency Injection
GL6 Ein Befehl, ein Build
Ein Projekt soll mit einem einzigen Befehl gebaut werden können. Dies erleichtert die Wartung und die Zusammenarbeit mit anderen Entwicklern.
GL7 Dokumentation
- Ein Projekt muss immer mit einem
README-Dokument beginnen, das eine kurze und lange Beschreibung des Projekts, Anweisungen zur Installation und Verwendung, sowie Informationen zur Lizenzierung und zum Beitrag enthält. - Der Standardtext, der von gitlab für readme-Dateien generiert wird, muss angepasst werden.
- Dokumentation über die Architektur und die Funktionsweise muss verlinkt oder im Projekt selbst enthalten sein.
GL8 Einsatz von Linter und Formatter
Von Anfang an sollen für Projekte Linter und automatische Code-Formatter eingesetzen, um sicherzustellen, dass der Code konsistent und fehlerfrei ist. Für alle Entwickler im Team müssen die gleichen Regeln konfiguriert werden, um konsistenten Code zu gewährleisten und VCS-Konflikte zu vermeiden.
GL9 Schreiben von Unit-Tests
Guter Code muss immer von Anfang an mit Tests begleitet werden. Tests helfen dabei, sicherzustellen, dass der Code nach dem Refactoring immer noch wie erwartet funktioniert.
GL10 Selbsterklärender Code und keine Kommentare
- Kommentare können lügen, Code nicht.
- Kommentare müssen vermieden werden, denn Kommentare veralten und ändern sich of nicht mit, wenn der Code geändert wird.
- Kommentare sind oftmals unverständlich, enthalten Rechtschreibfehler oder ergeben keinen Sinn zum Code.
- Wenn der Code nicht selbst erklärend ist, soll kein Kommentar geschrieben werden, sondern der Code soll umstrukturiert werden, um ihn verständlicher zu machen.
- Wenn ein Block von Code nicht selbst erklärend ist, soll dieser in eine eigene Methode ausgelagert werden, die einen aussagekräftigen Namen hat.
- Kommentare für Variablen oder Konstanten sollen vermieden werden und statt dessen aussagekräftige Namen verwendet werden.
- Kommentare für if-Bedingungen sollen vermieden werden und statt dessen der Term als aussagekräftige Variable oder Methode extrahiert werden.
- Kommentare dienen
- zur Erklärung von komplexen Algorithmen oder Geschäftsregeln, die nicht offensichtlich sind und nicht vereinfacht werden können.
- Meta-Informationen, die der Entwickler zur Klärung benötigt (z.B. warum etwas gemacht wurde).
- Entscheidungen, die getroffen wurden und nicht aus dem Code hervorgehen.
- TODOs, die noch erledigt werden müssen, erhalten dazu eine Ticketnummer.
Hinweis
Kommentare als Code Dokumentation (z.B. JavaDoc, JsDoc) sind eine Ausnahme und müssen immer verwendet werden.
INFO
Code Kommentare beschreiben, wie Code funktioniert (Das macht auch schon der Code selbst).
Code Dokumentation beschreibt wie Code verwendet werden soll, wozu er dient, welche Laufzeitbedingungen er hat und welche Fehler er werfen kann.
GL11 Einfachheit und nur das Notwendige
Guter Code soll einfach geschrieben und für andere Personen (im Team) leicht verständlich und ohne Überraschungen sein. Entwickler sollen sich nicht im Code selbst verwirklichen, sondern Code so schreiben, dass andere Entwickler ihn leicht verstehen, erweitern und verbessern können.
Um Code daher nicht unnötig komplex zu machen, darf daher auch nur das Notwendige implementiert werden, um die Anforderungen zu erfüllen. Das Vorgehen nach "Könnte später nützlich sein" soll vermieden werden und nur in Absprache mit dem Team umgesetzt werden.
Mögliche Konfigurationsparameter sollen nur dann implementiert werden, wenn sie auch wirklich benötigt werden. Jede neue Einstellung zur Laufzeit soll gut dokumentiert und getestet werden, damit sie nicht zu unerwartetem Verhalten führt. Jede unnötige Einstellung zur Laufzeit kann zu Fehlern und Missbrauch führen.
GL12 Ständiges Refactoring
Refactoring ist ein kontinuierlicher Prozess, um den Code sauber und wartbar zu halten und insbesondere sich den ständig neuen und ändernden Anforderungen anzupassen. Er ist verwandt mit der Boy Scout Rule (Hinterlasse den Code sauberer als du ihn vorgefunden hast).
Refactoring soll immer durchgeführt werden, wenn es notwendig ist, um den Code zu verbessern.
- Refactoring ändert nicht das Verhalten des Codes, sondern verbessert die Struktur und Lesbarkeit des Codes.
- Refactorings sollen nicht in einem separaten Ticket auf der To-Do-Liste stehen, sondern mit einer User Story oder einem Bugfix zusammen durchgeführt werden.
- Refactoring soll immer in kleinen Schritten durchgeführt werden.
- Refactoring soll immer mit Tests begleitet werden.
- Legacy-Code mit Tests abzudecken, ist ein Refactoring.
- Größere Refactorings sollen immer im Team abgesprochen werden. Lass dich aber nicht von einem Refactoring abhalten, wenn es notwendig ist.
- Größere Refactorings sollen parallel zum Tagesgeschäft und in kleinen Schritten (Divde and Conquer) über einen längeren Zeitraum durchgeführt werden.
Code altert nicht, aber er wird alt
Refactoring ist ein kontinuierlicher Prozess und sollte nicht als einmalige Aufgabe betrachtet werden.
Code ändert sich nicht (altert nicht), aber durch ändernde Anforderungen wird Code alt und muss daher angepasst werden, damit er für zukünftige Anforderungen gerüstet ist.
Aufwand von Refactoring vs. nicht durchgeführtes Refactoring
Aufwand durch Refactoring ist immer geringer als der Aufwand, der durch nicht durchgeführtes Refactoring entsteht.
Je öfter, früher und regelmäßiger Refactorings durchgeführt werden, desto geringer ist der Aufwand für die folgenden Refactorings.
Der Aufwand für neue Features und Bugfixes wird durch Refactoring reduziert, da der Code sauberer und wartbarer ist.
GL13 Einsatz von modellgetriebener Entwicklung
Es soll eine modellgetriebene Entwicklung bevorzugt werden, um die Softwareentwicklung zu verbessern und zu automatisieren.
Die modellgetriebene Entwicklung (Model Driven Development) ist ein Ansatz, bei dem die Softwareentwicklung auf Modellen basiert. Es hat den Vorteil, dass die Modelle unabhängig von der Implementierung sind und daher leichter zu verstehen und zu warten sind.
Dabei wird die Software durch Entitäten oder Domänenobjekte und deren Interaktion untereinander als abstraktes Modell in einer Sprache wie UML beschrieben (Modellierung). Das Modell kann dann, teilweise automatisiert, in Code umgewandelt werden.
Durch den Einsatz von Modellen soll außerdem eine Trennung von Datenobjekten und Geschäftslogik erreicht werden, um die Wartbarkeit und Erweiterbarkeit der Software zu verbessern.
Model Driven Development vs. Domain Driven Design
- Model Driven Development (MDE) konzentriert sich auf die Modellierung von Software. Es versucht, durch den Einsatz von Modellen auf höheren Abstraktionsebenen den Softwareentwicklungsprozess zu verbessern und zu automatisieren. Diese Modelle werden oft direkt in Code übersetzt (Code-Generierung). In MDE beschreibt man die Objekte (Entitäten) und ihre Beziehungen oft in Form von Modellen, z.B. UML-Diagrammen (Unified Modeling Language). Die Idee ist, dass man von diesen Modellen ausgeht und sie schrittweise verfeinert, bis sie entweder automatisch in lauffähigen Code umgewandelt werden oder als Grundlage für die Implementierung dienen. Die Interaktionen zwischen den Objekten können in den Modellen beschrieben werden und dann in eine Implementierung überführt werden, in der die verschiedenen Objekten über APIs, Methodenaufrufe oder Events miteinander interagieren.
- Domain Driven Design (DDE) hingegen konzentriert sich auf die Modellierung von Domänenwissen und die Implementierung von Software, die dieses Domänenwissen umsetzt. Dabei wird eine starke Trennung zwischen der Domäne und der technischen Implementierung vorgenommen. Das Domänenmodell steht dabei im Mittelpunkt und wird durch die Implementierung umgesetzt. Die Domänenobjekte spielen eine zentrale Rolle und werden durch die Geschäftslogik und nicht durch technische Aspekte bestimmt. In DDD werden Entitäten oft durch Begriffe aus der „Ubiquitous Language“ (eine gemeinsame Sprache zwischen Entwicklern und Fachexperten) beschrieben, sodass das Modell die Realität des Geschäfts widerspiegelt. In DDD wird die Interaktion zwischen den Entitäten durch bestimmte Muster wie Aggregate (Sammlung verwandter Entitäten), Repositories (Zugriff auf gespeicherte Entitäten) und Services strukturiert. Diese Interaktionen spiegeln die realen Geschäftsprozesse wider, die die Entitäten repräsentieren.
GL14 Performance-Optimierungen
Auf Optimierung ohne Grund soll verzichtet werden.
- Code soll zuerst nach allen Regeln und Prinzipien geschrieben und automatisiert getestet werden.
- Optimierungen dürfen nur mit einem Benchmark durchgeführt werden, um das Optimierungsergebnis zu überprüfen.
GL15 Einheitliche Fehlerbehandlung
- Fehler/Ausnahmen sollen einheitlich über den gesamten Code behandelt werden.
- Das Framework oder eine globale Fehlerbehandlung behandelt allgemeine Fehler und informiert den Benutzer.
- Spezifische Fehlerbehandlungen (
try-catch) sollen nur verwendet werden, wenn ein Fehler bekannt und im Code behandelbar ist. - Abgefangene Fehler/Ausnahmen sollen entweder geloggt oder weitergegeben werden, aber nicht beides, um Doppelungen beim Loggen zu vermeiden.
- Abgefangene Fehler/Ausnahmen können in Ausnahmefällen und mit Kommentar auch ignoriert werden.
- Die Fehlerbehandlung muss immer berücksichtigt und immer getestet werden.
- Tests müssen auch die Fehlerbehandlung abdecken.
- Auch seltene oder unmöglich erscheinende Fehler müssen getestet werden.
- Fehler müssen so früh wie möglich geworfen werden (siehe Fail Fast).
- Fehler sollen anhand ihres Abstraktionsgrades geworfen werden
- Fehler von niederen Schichten sollen in höheren Schichten in Domänen-spezifische Fehler umgewandelt werden (gewrappt werden).
Globale Fehlerbehandlung der lokalen Fehlerbehandlung vorziehen
Lokale Fehlerbehandlung ist die Verwendung von try-catch-Blöcken, Status-Wert-Abfrage, Promise.catch oder ähnlichen Mechanismen, um Fehler zu behandeln, die in einem bestimmten Codeabschnitt auftreten können.
Globaler Fehlerbehandlung ist die Verwendung eines zentralen Mechanismus, um Fehler zu behandeln, die nicht lokal behandelt werden. Oftmals stellt das eingesetzte Framework eine globale Fehlerbehandlung zur Verfügung, die verwendet werden kann, um z.B. dem Benutzer eine Fehlermeldung anzuzeigen.
Die Globale Fehlerbehandlung ist einfacher zu implementieren und zu warten und führt zu verständlicheren Code. Wenn eine lokale Fehlerbehandlung wie mit try-catch-Blöcken verwendet wird, muss die Behandlung der möglichen Fehler manuell implementiert werden. Oftmals wird jedoch die Fehlerbehandlung vollständig vergessen oder ignoriert (und auch nicht getestet). Inkonsistente Fehlerbehandlung kann zu unerwartetem Verhalten führen. Beispielsweise kann ein Fehler in einem Modul mit einem Dialog angezeigt werden, während ein anderes Modul den Fehler ignoriert oder nur im Log ausgibt. Die entsprechenden Aufrufer der Module können dann nicht mehr unterscheiden, ob ein Fehler aufgetreten ist oder nicht.
GL16 Verwenden aussagekräftige Rückgabewerte und -typen
Wenn eine Methode einen Wert zurückgibt, soll dieser Wert aussagekräftig sein und genau das darstellen, was die Methode tut. Es ist auch hilfreich, konsistente Rückgabetypen zu verwenden.
GL17 Gesetz von Demeter
Objekte sollen nur mit Objekten kommunizieren, die sie direkt kennen. Das bedeutet, dass ein Objekt nur Methoden von Objekten aufrufen soll, die es selbst erstellt hat, die als Parameter übergeben wurden oder die es als Eigenschaft besitzt. Dies verhindert eine zu starke Kopplung zwischen den Objekten.
Um dies zu verhindern kann Dependency Injection verwendet werden.
Beispiel:
// schlecht
person.department().manager().address().streetName();
// statt dessen
addressDI.streetName();GL18 Einheitliche Namensgebung
Code wird öfters gelesen als geschrieben. Daher ist es wichtig, dass die Namensgebung konsistent und aussagekräftig ist.
Detailliertere Regeln dazu findest du in Einheitliche Namensgebung.
INFO
Gute Code beschreibt sich selbst.
GL19 Sicherheit
Sicherheit in der Entwicklung ist eine nicht-funktionale Anforderung, die in jedem Schritt der Softwareentwicklung berücksichtigt werden muss.
Allgemein gilt:
- Prüfung der Authentifizierung und Autorisierung
- Prüfung der Eingaben auf Gültigkeit und Sicherheit
- Benutzereingaben sind immer als unsicher zu betrachten
- Aktualisierung der verwendeten Bibliotheken
- Einsatz von Tools zur statischen Codeanalyse und Prüfung der Abhängigkeiten
Authentifizierung vs. Autorisierung
Authentifizierung ist der Prozess, bei dem die Identität eines Benutzers überprüft wird.
Autorisierung ist der Prozess, bei dem überprüft wird, ob ein Benutzer auf bestimmte Ressourcen zugreifen darf.
Fehlende Eingabeprüfung
Die fehlende oder ungenügende Prüfung von Benutzereingaben ist die häufigste Ursache für Sicherheitslücken.
GL20 Behebung der Wurzel des Problems
Es soll immer die Wurzel des Problems behoben werden und nicht nur die Symptome.
- Symptome sind oft nur die Auswirkungen eines tieferliegenden Problems.
- Temporäre Lösungen bleiben oft bestehen und führen zu weiteren Problemen.
- Bei der Suche des eigentlichen Ursache werden oft weitere Probleme entdeckt und behoben.
GL21 Logging
GL21 Logging-Stufen
Logging gibt es in verschiedenen Stufen
- Debug: Detaillierte Informationen für die Entwickler
- Info: Informationen über den Ablauf des Programms
- Warn: Warnungen, die auf Probleme hinweisen, die behoben werden sollten, aber nicht dazu führen, dass das Programm nicht funktioniert.
- Error: Fehler, die das Programm möglicherweise zum Absturz bringen und die behoben werden müssen.
GL21 Logging-Regeln
Generell gilt: Gut designte Anwendungen haben nur wenige Codezeilen, die Loggen. Es soll nicht auf Verdacht geloggt werden, sondern nur wenn es notwendig ist.
GL21 Logging soll von fachlichen Code getrennt sein
Durch den Einsatz von Aspekt-Orientierter Programmierung (AOP) kann Logging von fachlichen Code getrennt werden. Dadurch wird der fachliche Code nicht durch Logging-Code verunreinigt und bleibt übersichtlich.
Ein Logging geschieht indem ein Decorator-Pattern verwendet wird, um den fachlichen Code zu umhüllen und das Logging zu implementieren.
In Beispielcodes von Logging-Frameworks wird oft eine statische Variable verwendet, um den Logger für eine Business-Klasse zu erhalten. Dies ist jedoch nicht empfohlen, da dadurch der Logger nicht ausgetauscht werden kann und das Logging nicht komplett deaktiviert werden kann (z.B. auch für Tests).
Beispiel für Logging mit Decorator-Pattern
Im Folgenden wird ein Beispiel für das Logging mit dem Decorator-Pattern gezeigt. Dazu wird eine Business-Logik-Klasse mit einem Decorator umhüllt, der das Logging übernimmt.
// Interface für die Business-Logik
interface BusinessService {
execute(data)
}
// Konkrete Implementierung der Business-Logik
class BusinessServiceImpl implements BusinessService {
execute(data) {
// Business-Logik hier
// z.B. Verarbeite Daten, führe Berechnungen durch, etc.
return "Result of business logic"
}
}
// Decorator, der Logging übernimmt, um die Business-Logik zu umhüllen und
// beispielsweise die Ausführungsdauer zu loggen
class LoggingPerfomanceDecorator implements BusinessService {
// Referenz auf die eigentliche Business-Logik
private wrappedService: BusinessService
private Logger logger;
// Konstruktor, um den zu dekorierenden Service zu übergeben
constructor(service: BusinessService, loggerFactory: LoggerFactory) {
this.wrappedService = service
this.logger = loggerFactory.getLogger(service.getClass())
}
execute(data) {
// Vor dem Aufruf: Log-Eintrag erstellen
logger.info("Starting execution of business logic with data: " + data)
// Aufruf der eigentlichen Business-Methode
result = this.wrappedService.execute(data)
// Nach dem Aufruf: Log-Eintrag erstellen
logger.info("Finished execution. Result: " + result)
return result
}
}
// Beispielhafte Nutzung
// Erstellen der Business-Logik-Instanz
service = new BusinessServiceImpl()
// Dekorieren mit Logging-Funktionalität
loggedService = new LoggingPerfomanceDecorator(service)
// Aufruf der Methode; dabei werden Log-Meldungen erzeugt
loggedService.execute("Beispieldaten")GL21 Kleine Methoden
Wenn Methoden klein sind, ist es einfacher, das Logging zu implementieren. Durch die Reihenfolge von Log-Ausgaben ist es einfacher möglich den Ablauf des Programms zu verstehen, wenn die Methoden klein sind und in einem Call-Stack sichtbar sind.
- Logging soll nicht in Getter- und Setter-Methoden erfolgen.
- Logging soll nicht in Konstruktoren erfolgen.
- Logging soll nicht in statischen Methoden erfolgen.
GL21 Logging nur, wenn notwendig
Logging soll generell nur dann erfolgen, wenn es notwendig ist, um ein Problem zu identifizieren.
- Es sollen nur Werte geloggt werden, die nicht bei einer Auswertung der Loggings selbst ermittelt werden können (z.B. keine Konstanten, pure Methodenaufrufe).
- Werte sollen nur dann geloggt werden, wenn sie für die Analyse notwendig sind.
- Sensible Daten sollen nicht geloggt werden (z.B. Passwörter, personenbezogene Daten).
GL21 Performance
Übermäßiges Logging kann die Performance beeinträchtigen, insbesondere, wenn Logs innerhalb von Schleifen oder bei jedem Methodenaufruf geschrieben werden.
GL21 Aussagekräftige Log-Meldungen
Log-Meldungen sollen aussagekräftig sein und den Kontext der Meldung enthalten. Dies bedeutet, dass ganze Sätze verwendet werden sollen, die den Kontext der Meldung beschreiben.
- Log-Meldungen sollen in Englisch verfasst werden.
- Log-Meldungen sollen auch von anderen Personen als Entwickler verstanden werden.
- Log-Meldungen sollen Rechtschreibung und Grammatik beachten.
- Log-Meldungen sollen Platzhalter verwenden, die durch das Logging-Framework ersetzt werden (z.B.
log.debug("User {} logged in", user.getName())).
Wichtig: Log-Meldungen sollen eindeutig sein und nicht mehrfach ausgegeben werden oder an mehreren Stellen im Code identisch sein.
Schlechte Log-Meldung
Zu vage: An error occurred.
Zu technisch: NullReferenceException: Object reference not set to an instance of an object.
Zu unverständlich: 0x0000005: Access violation.
Unbekannte Abkürzungen: DBMS error: SQLERR 1234.
Spam: [INFO] Processing data... [INFO] Processing data... [INFO]Processing data...
Falsches Log-Level: [DEBUG] Database connection failed.
Persönliche Informationen: User 123 logged in with password 123456. Rechtschreibfehler: Conection to database faild.
Gute Log-Meldung
Klar und informativ: [ERROR] Could not open file: config.yaml (Permission denied)
Kontext: [INFO] User 'admin' logged in successfully (IP: 143.23.12.31)
Fehlerbehebung: [WARN] Database connection failed. Retrying in 5 seconds.
Lösungsvorschlag: [ERROR] Could not connect to database (Timeout). Check network connection.
Richtiges Log-Level:[ERROR] Could not connect to database.[INFO] Server started on port 8080. [WARN] High CPU usage detected (85%) [ERROR] Database connection failed: The connection was rejected by the server.
Vollständige Sätze: [WARN] Could not connect to database. A timeout occurred after 10 seconds.
Platzhalter: [INFO] User {} logged in from {} (IP: {}), user.getName(), user.getLocation(), user.getIp()
GL21 Log-Level
Eine Log-Meldung soll im Code nur dann ausgegeben werden, wenn das entsprechende Log-Level aktiviert ist. Gegebenenfalls muss eine Log-Meldung auch mit einem if-Statement oder anderen Conditional-Patterns umgeben werden, um die Ausgabe zu verhindern.
GL21 Log-Framework
Log-Meldungen sollen mit einem durch das Framework bereitgestellten Logger ausgegeben werden. Direktes Ausgeben von Log-Meldungen auf der Konsole oder in Dateien ist für Produktivumgebungen nicht erlaubt.
Vermeide eine Neuerfindung des Logging-Rades und verwende ein Logging-Framework, das die Anforderungen erfüllt und für die Umgebung standardisiert ist.
console in Web-Umgebungen
Das console-Object in der Web-Umgebung ist mächtig und moderne Web-Browser unterstützen das Logging mit vielen Funktionen. Generell ist es nicht notwendig, ein zusätzliches Logging-Framework in Web-Umgebungen zu verwenden, da das console-Object ausreichend ist.
GL21 Log-Texte enthalten die folgenden Informationen
- Datum und Uhrzeit (durch das Logging-Framework)
- Log-Level (durch das Logging-Framework)
- Klassenname und Methode (durch das Logging-Framework)
- Nachricht, eins oder mehrere von:
- Was ist passiert? (Fehler beim Ausführen von Methode X)
- Was ist der Kontext? (Methode, Datenbank, Datei, Benutzer, etc.)
- Was ist das Problem? (SQL Fehler, Datei nicht gefunden, Benutzer gesperrt, etc.)
- Lösungsvorschlag, wenn möglich
GL22 Vertikaler Abstand
- Code soll vertikal unterteilt werden, um die Lesbarkeit zu verbessern.
- Code, der zusammengehört, soll zusammenstehen.
- Variablen, die zusammengehören, sollen zusammenstehen.
- Variablen sollen so nah wie möglich an ihrer Verwendung deklariert werden.
- Konstante Variablen sollen getrennt von anderen Variablen deklariert werden.
- Funktionen/Methoden gleichen Typs (statisch, Instanz) sollen oberhalb ihrer Verwendung deklariert werden.
void exampleMethode() {
final int MAX_COUNT = 10;
// Trennung von Konstanten und Variablen
// Variable steht zusammen mit ihrer Verwendung
int exampleCounter = 0;
for (int i = 0; i < 10; i++) {
exampleCounter += i;
}
// Leerzeile
int nextCounter = 0;
for (int i = 0; i < 10; i++) {
nextCounter += i;
}
}
// Leerzeile
// hier weitere Methoden, die exampleMethode verwenden
exampleMethode();GL23 Parameter prüfen
Parameter von öffentlichen Methoden/Funktionen müssen geprüft werden, um unerwartete Werte zu verhindern.
Dies kann auf unterschiedliche Weise erfolgen:
- Sprachen wie Java unterstützen Annotationen, um Parameter zu prüfen.
- Linter können verwendet werden, um Parameter und Eingaben zu prüfen, ob sie gültig sind.
- Manuelle Prüfungen können durchgeführt werden, um sicherzustellen, dass die Parameter gültig sind.
Hauptsächliche Probleme bei Parameter sind:
- Null-Prüfung: Parameter dürfen nicht null sein, wenn sie nicht null sein dürfen.
- Bereichsprüfung: Parameter müssen innerhalb eines bestimmten Bereichs liegen.
- Typprüfung: Parameter müssen den erwarteten Typ haben.
- Längenprüfung: Parameter müssen eine bestimmte Länge haben.
- Formatprüfung: Parameter müssen einem bestimmten Format entsprechen.
- Gültigkeitsprüfung: Parameter müssen bestimmten willkürlichen Regeln entsprechen.
NullPointer-Exception ist keine Parameterprüfung
NullPointer-Exceptions sind keine Parameterprüfungen, sondern Fehlerbehandlungen, die durch die Sprache zur Laufzeit durchgeführt werden. Oftmals beinhalten diese Meldungen keine Informationen, welcher Parameter null war und sollen daher durch eine separate Parameterprüfung mit Erklärung ersetzt werden.
GL24 Trennung von Verantwortlichkeiten
Es sollen Methoden, Klassen und Module nur die Aufgaben erfüllen, für die sie zuständig sind.
Dies entspricht Single Responsibility Principle (SRP) aus den Prinzipien der Softwareentwicklung. SOLID
Das bedeutet:
- Klassen und Methoden haben nur eine Aufgabe und erfüllen diese.
- Es gibt keine Gott- oder Utility Klassen, die alle Methoden enthalten.
Umgesetzt wird dies durch:
- Aufteilung von Klassen und Methoden in kleinere Einheiten.
- Verwendung von Dependency Injection, um Abhängigkeiten zu verwalten.
- Abstrahierung von Klassen durch Schnittstellen (Interfaces).
- Verwendung von Design Patterns, um die Verantwortlichkeiten zu trennen.
- Verwendung von immutable Objekten (Value-Objects) und Information Hiding.
GL24 Vorteile
- Übersichtlicher Code durch kleinere Einheiten
- Einfachere Wartung, durch weniger Komplexität, weil einzelne Methoden und Klassen weniger Aufgaben haben und dadurch kleiner sind.
- Einfachere Tests, da einzelne Methoden und Klassen einfacher zu testen sind.
GL25 Länge von Methoden/Funktionen
Oftmals bestehen Methoden/Funktionen aus vielen Zeilen Code, die aus Kombinationen von logischen (if, while) und operativen Anweisungen (Aufrufen) bestehen. Diese Methoden/Funktionen sind oft schwer zu verstehen und zu testen.
Die Länge von Methoden/Funktionen ist daher soweit klein zu halten, dass sie nur eine Aufgabe erfüllen und leicht zu verstehen sind.
Eine Methode oder Funktion sollte möglichst klein sein und höchstens 7 verschiedene Fälle behandeln. Das liegt daran, dass Menschen nur etwa 7 Informationseinheiten gleichzeitig verarbeiten können (bekannt als Miller’s Law). Dabei geht es nicht um die Anzahl der Zeilen im Code, sondern um die Anzahl der unterschiedlichen Fälle, die die Methode behandelt.
Folgende Schritte können unternommen werden, um die Länge von Methoden/Funktionen zu reduzieren:
- Extrahieren von Code in eigene Methoden/Funktionen (Single Responsibility Principle)
- Business-fremde Logik in eigene Klassen oder Module auslagern (Separation of Concerns, Einsatz von modellgetriebener Entwicklung)
- Schleifen oder Schleifenkörper in eigene Methoden/Funktionen extrahieren
- Ausnahmebehandlung dem Framework überlassen oder in eigene Methoden/Funktionen extrahieren (Decorator-Pattern)
- Auftrennen der Methoden/Funktionen in logische und operative Methoden/Funktionen (Trennung von operationalem und integrativem Code)
Anhaltspunkte wie maximal groß eine Methode/Funktion sein sollte sind:
- Die Anzahl der Zeilen soll eine durchschnittliche Bildschirmhöhe nicht überschreiten, damit die Methode/Funktion auf einen Blick erfasst werden kann.
- 24 Zeilen (einschließlich Leerzeilen) können auf einen Blick erfasst werden.
- Die Menge an Informationen, die ein menschliches Gehirn gleichzeitig verarbeiten kann sind 7±2 (Miller's Law).
- Unit-Tests sind zu groß und komplex (7±2 Fälle).
Miller's Law
Millers Law, benannt nach dem Psychologen George A. Miller, besagt, dass ein Mensch durchschnittlich nur etwa 7 ± 2 Informationseinheiten (Chunks) gleichzeitig im Kurzzeitgedächtnis halten kann.
Millers Law hilft Software intuitiver, verständlicher und wartbarer zu gestalten, indem es die kognitiven Grenzen des Menschen berücksichtigt.
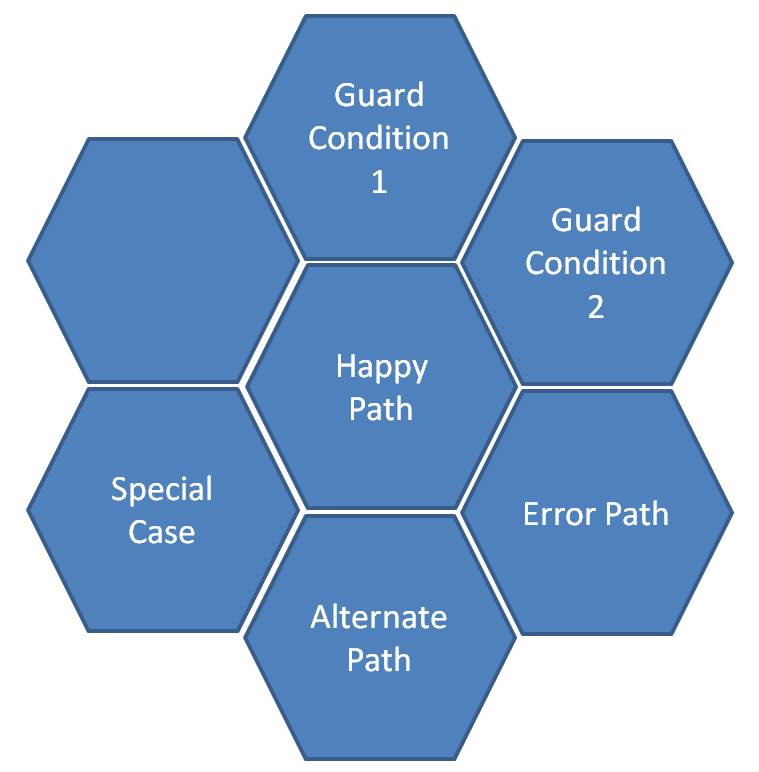 Fälle pro Methode nach Mark Seemann können als hexagonale Form dargestellt werden.
Fälle pro Methode nach Mark Seemann können als hexagonale Form dargestellt werden.
GL26 Niedrige Kopplung
Oftmals sind Klassen und Methoden so miteinander verbunden, dass eine Änderung in einer Klasse oder Methode eine Änderung in einer anderen Klasse oder Methode erfordert. Dies führt zu einer hohen Kopplung zwischen den Klassen und Methoden.
Hohe Kopplung kann verhindert werden durch:
- Einsatz von Architekturmustern, um die Kopplung zu verringern (Schichtenarchitektur, Pipes and Filters, Microservices, Hexagonale Architektur/Ports and Adapters).
- Verwendung von Schnittstellen (Interfaces) und abstrakten Klassen, um die Kopplung zu verringern.
- Verwendung von Dependency Injection, um Abhängigkeiten zu verwalten.
- Verwendung von Design Patterns, um Klassen, deren Abstraktion und Implementierung voneinander zu trennen (Adapter, Bridge, Mediator).
Schnittstellen
Niedrige Kopplung wird hauptsächlich durch Schnittstellen erreicht. Verwende daher immer Schnittstellen, um die Kopplung zwischen Klassen zu verringern.
Der zusätzliche Aufwand rechnet sich, wenn die Klassen getestet oder erweitert werden müssen.
Welche Arten von Kopplungen es gibt, können in Kopplung nachgelesen werden.
GL27 Nebeneffekte vermeiden
Methoden und Funktionen sollen keine Nebeneffekte haben, die nicht offensichtlich sind.
- Eine Methode oder Funktion soll keine Parameter oder die Inhalte der Parameter verändern.
- Eine Methode oder Funktion soll keine internen Zustände nach außen sichtbar machen.
- Eine Methode oder Funktion soll keine globalen Variablen verändern.